
Source: https://arxiv.org/pdf/2511.07885
Listen in multiple languages, when available:
1. Key Findings
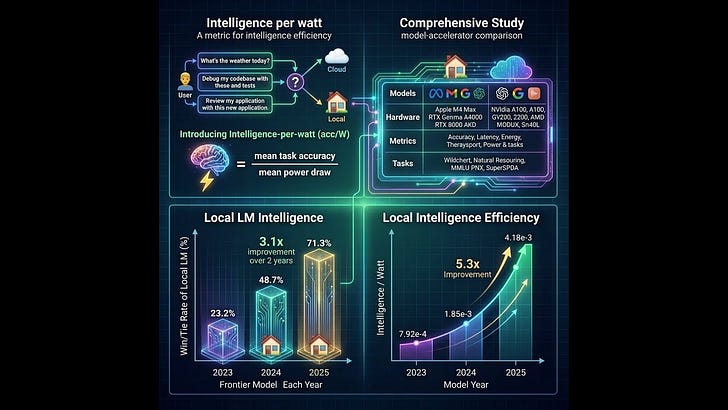
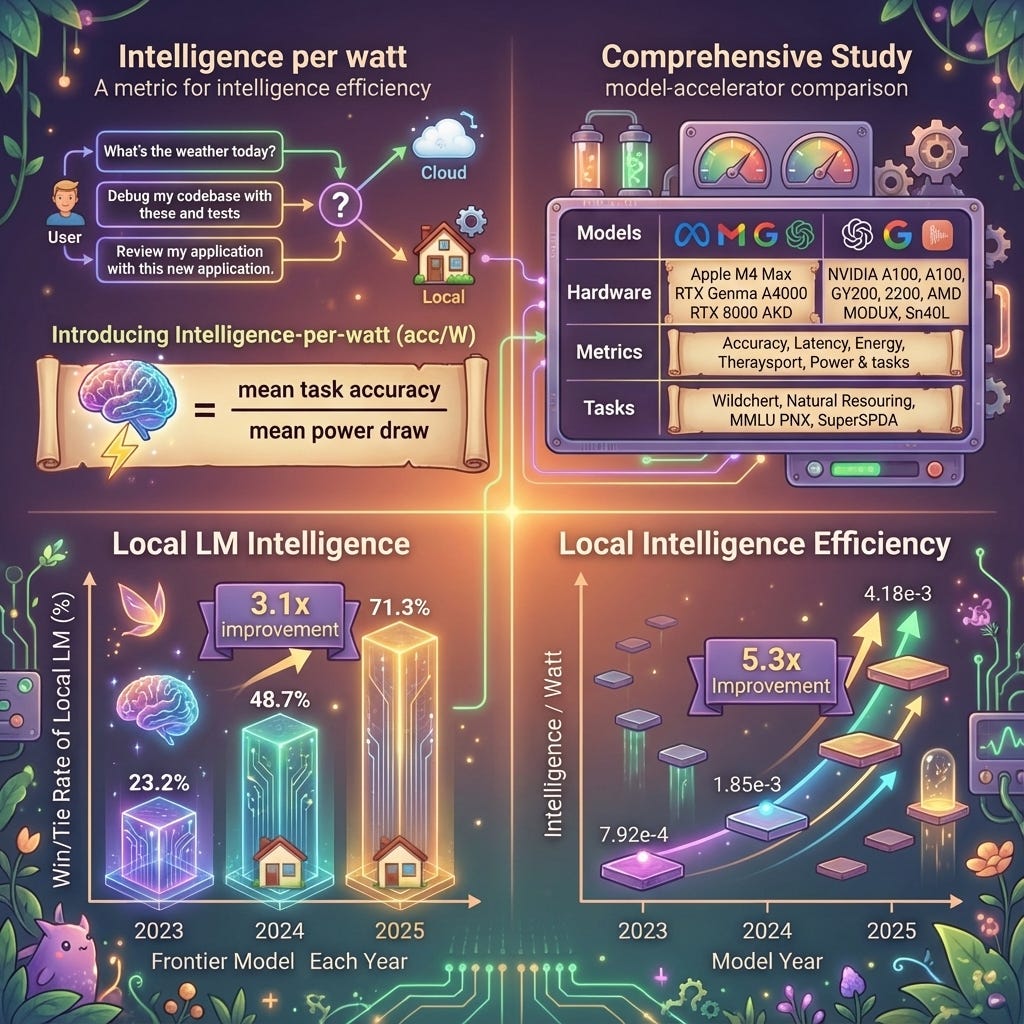
- Introduces a unified metric—intelligence per watt (IPW)—to measure both capability and efficiency of local AI: “task accuracy divided by unit of power.”
- Local LMs can successfully answer 88.7% of single-turn chat and reasoning queries, with coverage varying by domain (90%+ in creative; ~68% in technical fields).
- IPW improved 5.3× from 2023–2025, driven by both model (≈3.1×) and accelerator (≈1.7×) advances; locally serviceable query coverage rose from 23.2% (2023) to 71.3% (2025).
- Local accelerators currently trail cloud accelerators: “local accelerators achieve at least 1.4× lower IPW than cloud accelerators running identical models,” indicating optimization headroom.
- Hybrid local-cloud routing yields substantial resource savings:
- Oracle routing: −80.4% energy, −77.3% compute, −73.8% cost vs cloud-only.
- Realistic routing (80% accurate): −64.3% energy, −61.8% compute, −59.0% cost with no quality loss due to cloud fallback.
- Model diversity plus intelligent routing significantly boosts coverage: best-of-local routing achieves 88.7% overall coverage, beating any single local model by 16–29 percentage points.
- Cloud accelerators have higher energy efficiency per query:
- Intelligence per joule is 1.6–2.3× higher on NVIDIA B200 vs Apple M4 Max, and 6.5–7.4× higher on SambaNova SN40L for evaluated models.
- Local accelerator memory has expanded rapidly (10–20 GB in 2020 to 128–512 GB in 2025), enabling on-device hosting of 8–20B active parameter models at interactive latencies.
- The study spans 1M+ queries across realistic chat and reasoning workloads and standardized benchmarks (WILDCHAT, NATURALREASONING, MMLU PRO, SUPERGPQA).
Notable quotes
- “We propose intelligence per watt (IPW), task accuracy divided by unit of power, as a unified metric…”
- “Local LMs can successfully answer 88.7% of single-turn chat and reasoning queries…”
- “IPW improved 5.3×, driven by both algorithmic advances and accelerator improvements…”
- “Local accelerators achieve at least 1.4× lower IPW than cloud accelerators… revealing significant headroom for local accelerator optimization.”
- “Oracle routing… could reduce energy consumption by 80.4%, compute by 77.3%, and cost by 73.8% versus cloud-only deployment.”
- “A routing system with 80% accuracy… achieves 64.3% energy reduction, 61.8% compute reduction, and 59.0% cost reduction with no degradation in answer quality.”
- “These findings establish local inference as a practical complement to centralized infrastructure…”
2. Key Concepts
- Intelligence per Watt (IPW): A capability-efficiency metric defined as accuracy per unit power (accuracy per watt).
- Intelligence per Joule (IPJ): Accuracy per unit energy (accuracy per joule), incorporating latency effects.
- Complementary efficiency metrics:
- APW (Accuracy per Watt)
- PPW (Perplexity per Watt)
- APJ (Accuracy per Joule)
- PPJ (Perplexity per Joule)
- Local vs Cloud Inference: Local models (≤20B active parameters) on consumer accelerators vs frontier models (≥100B parameters) on cloud/enterprise accelerators.
- Routing: Assigning each query to the smallest capable model; best-of-local routing leverages model diversity for higher coverage.
- Profiling harness: Hardware-agnostic system to measure accuracy, latency, energy, TTFT, power, and telemetry with 50 ms sampling; supports NVIDIA, AMD, Apple Silicon.
- Benchmarks and traffic:
- WILDCHAT (500K chat prompts)
- NATURALREASONING (500K reasoning queries)
- MMLU PRO (12K multi-domain knowledge)
- SUPERGPQA (26.5K graduate-level reasoning across 285 disciplines)
- Domain labeling: Anthropic Economic Index categories for economic relevance of tasks.
3. Applications in Business
- Cost and energy optimization:
- Implement hybrid local-cloud routing to reduce operational energy, compute, and cost by 40–65% under realistic router accuracy.
- Use IPW/IPJ to inform procurement (accelerator selection), deployment decisions, and sustainability targets.
- Edge product strategies:
- On-device AI for privacy, lower latency, and reduced cloud dependency for 70–90% of single-turn workloads (especially chat, writing, and general information tasks).
- Capacity management:
- Redistribute inference demand from constrained cloud resources to local devices, alleviating data center power and capex pressures.
- SLA design and routing policies:
- Configure fallback to frontier models for technical domains and hard reasoning tasks; maintain quality while capturing efficiency gains.
- Model portfolio management:
- Exploit model diversity—route queries to specialized local models by task type/category for improved coverage and performance.
- Sustainability reporting:
- Quantify energy savings in TWh at platform scale; align with corporate ESG goals as AI workloads grow.
- Workforce enablement:
- Target economically valuable domains (Arts & Media, Business Operations) for local processing, reserving cloud capacity for specialized technical workloads.
4. Important Insights
- Local LMs now meet most single-turn user needs: “local models can accurately handle significant portions of single-turn chat and reasoning queries.”
- Efficiency gains are compounding and predictable across models and hardware, supporting a sustained shift toward local inference.
- Model diversity and routing are force multipliers—coverage and efficiency significantly improve beyond any single model’s performance.
- Per-watt vs per-joule metrics matter:
- Per-watt (IPW) captures instantaneous efficiency; per-joule (IPJ) captures end-to-end efficiency including latency, accentuating cloud accelerators’ advantage.
- Domain-specific performance:
- Creative/humanities tasks are highly amenable to local processing; technical disciplines (Architecture & Engineering, advanced STEM) still benefit from frontier models.
- Hardware trajectory:
- Rapid growth in local accelerator memory is a key enabler of on-device AI; specialized on-device AI components could close the remaining efficiency gap.
- Infrastructure implications:
- At scale, intelligent routing can deliver TWh-level energy savings annually; a practical pathway to manage the projected AI-driven surge in data center demand.
5. Challenges and Solutions
- Main challenge
- Exponential growth in LLM inference demand strains centralized cloud infrastructure and power systems.
- Key obstacles
- Efficiency gap: Local accelerators have lower IPW/IPJ vs cloud accelerators (≈1.4× lower IPW; up to 7.4× lower IPJ on some workloads).
- Domain difficulty: Technical reasoning tasks show lower local coverage; hardest reasoning problems improve slower.
- Measurement fidelity: Software-based power telemetry can have 10–15% inaccuracies; differences across CPU/GPU/NPU architectures complicate comparisons.
- Routing accuracy: Imperfect query-to-model assignment reduces realized savings (needs robust routers to approach oracle gains).
- Expert notions of solution
- Unified efficiency metrics: “IPW serving as the critical metric for tracking this transition” and guiding system and hardware optimization.
- Hybrid local-cloud systems: Treat local and cloud as complementary resources; route to smallest capable local model, fallback to frontier models as needed.
- Model diversity and specialization: Use multiple local models (architectural, pretraining, post-training diversity) to capture complementary strengths.
- Hardware advancements: Invest in specialized on-device AI components (HBM-like memory, tensor cores, optimized memory hierarchies) to close IPW/IPJ gaps.
- Overcoming limitations
- Routing with cloud fallback: Achieve large savings even at 60–80% router accuracy while maintaining answer quality.
- Continued algorithmic progress: Pretraining, post-training (RLHF, DPO), MoE, and instruction tuning to boost local model capability on technical tasks.
- Robust measurement: Release of a cross-platform profiling harness; 50 ms telemetry sampling; multi-GPU energy aggregation; normalization for reproducible benchmarking.
- New techniques
- IPW and IPJ as core metrics for intelligence efficiency.
- A hardware-agnostic profiling harness for reproducible, system-level energy and latency telemetry.
- Large-scale, real-world workload evaluation (1M+ queries) combined with standardized benchmarks and economic task categorization.
- Broader implications
- Strategic rebalancing of AI workloads across edge and cloud, reducing energy and capital demands during rapid AI adoption.
- Policy and ESG impacts: measurable pathways to curb data center growth (projected 156–219 GW by 2030; $5.2–$7.9T capex) and manage grid load (U.S. 50 GW by 2030).
- Accelerated time-to-value: Frontier-grade capabilities reaching consumer hardware within ~1 year; expanding feasibility of on-device AI products and services.
Created with AI