Source: https://storage.googleapis.com/deepmind-media/DeepSearchQA/DeepSearchQA_benchmark_paper.pdf
Listen in multiple languages, when available:
1. Key Findings
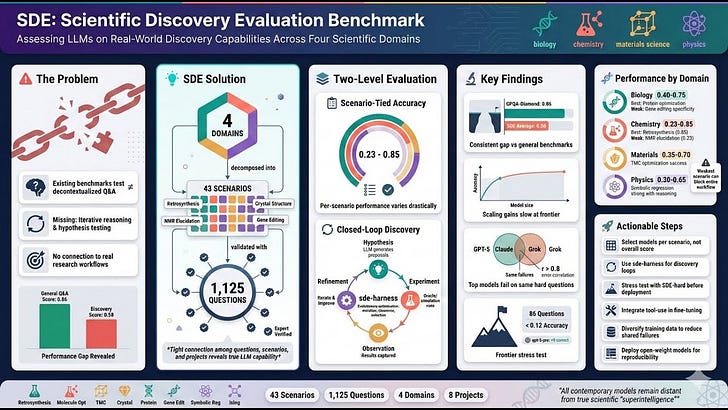
- DeepSearchQA introduces a 900‑prompt benchmark across 17 fields to evaluate deep, multi‑step information‑seeking agents on exhaustive set generation rather than single-answer retrieval.
- The benchmark explicitly tests three under-evaluated capabilities:
- Systematic Collation across disparate sources.
- Entity Resolution (de-duplication).
- Reasoning about Stopping Criteria in open-ended search spaces.
- Outcome-based evaluation focuses on the submitted set’s Precision, Recall, and F1, plus strict categorical outcomes: Fully Correct, Fully Incorrect, Partially Correct, and Correct with Extraneous Answers.
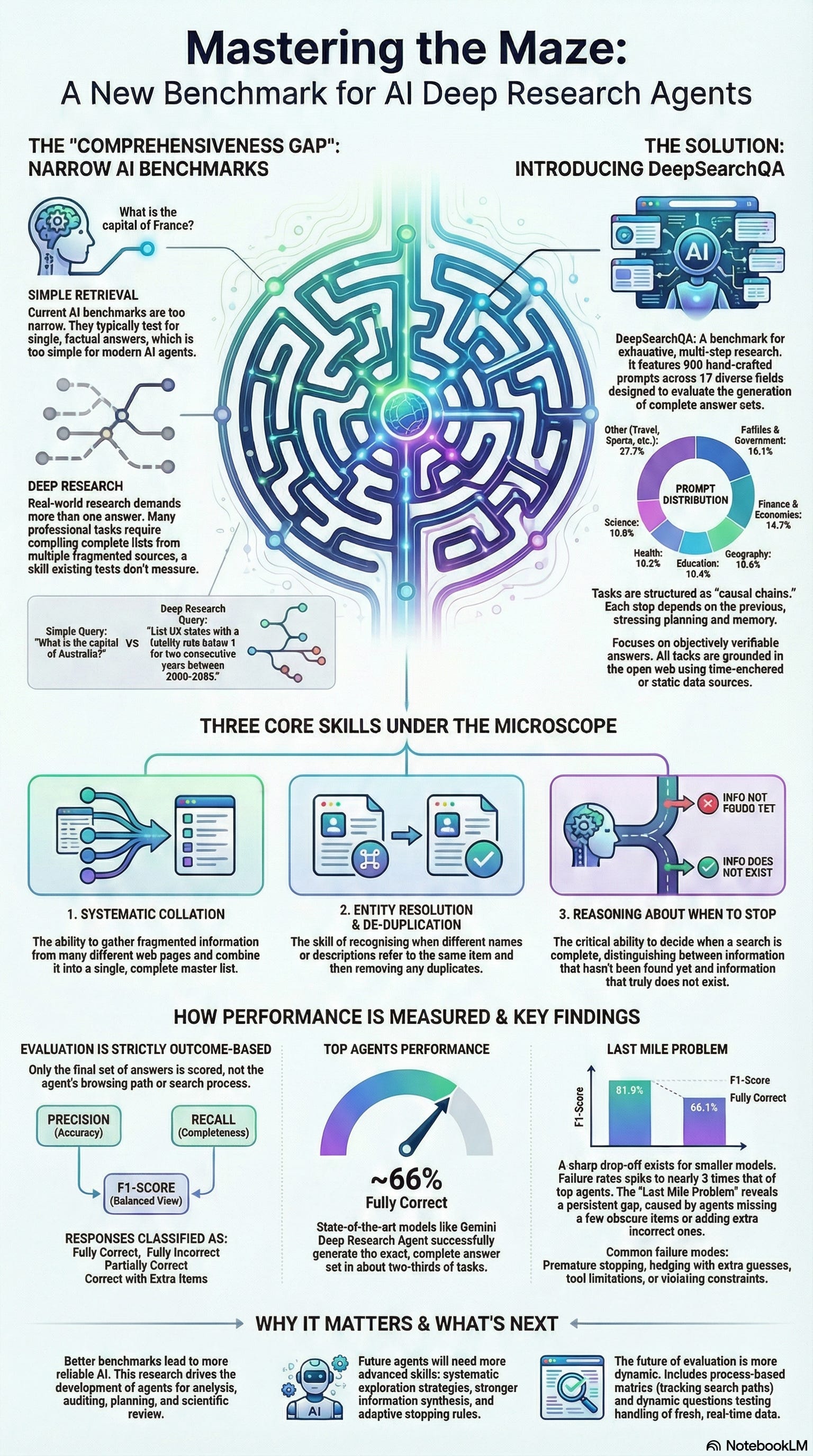
- State-of-the-art agents show strong but imperfect performance:
- Gemini Deep Research Agent: Fully Correct 66.09%, Fully Incorrect 9.95%, F1 81.90.
- GPT-5 Pro High Reasoning: Fully Correct 65.18%, Fully Incorrect 14.13%, F1 78.98.
- There is a pronounced “Last Mile Problem”: a ~15-point gap between high F1 and strict Fully Correct (S=G), driven by under-retrieval and over-retrieval failure modes.
- Scaling behavior indicates a hard reasoning threshold; performance drops steeply for smaller models (e.g., Gemini 2.5 Flash F1 42.99, Fully Incorrect 45.27%).
- Distinct failure modes identified: premature stopping, hedging with low-confidence extras, tool limitations (e.g., unreadable files), quantitative estimation errors, and constraint-violation in filtering.
- Quotes:
- “This shift in design explicitly tests three critical, yet under-evaluated capabilities: 1) systematic collation... 2) de-duplication and entity resolution... and 3) the ability to reason about stopping criteria...”
- “Performance is judged solely on the completeness (recall) and correctness (precision) of the final set submitted by the agent, rather than the search trajectory used to obtain it.”
- “We observe distinct failure modes ranging from premature stopping (under-retrieval) to hedging behaviors...”
- “This gap represents the ‘Last Mile Problem’ in autonomous deep research.”
2. Key Concepts
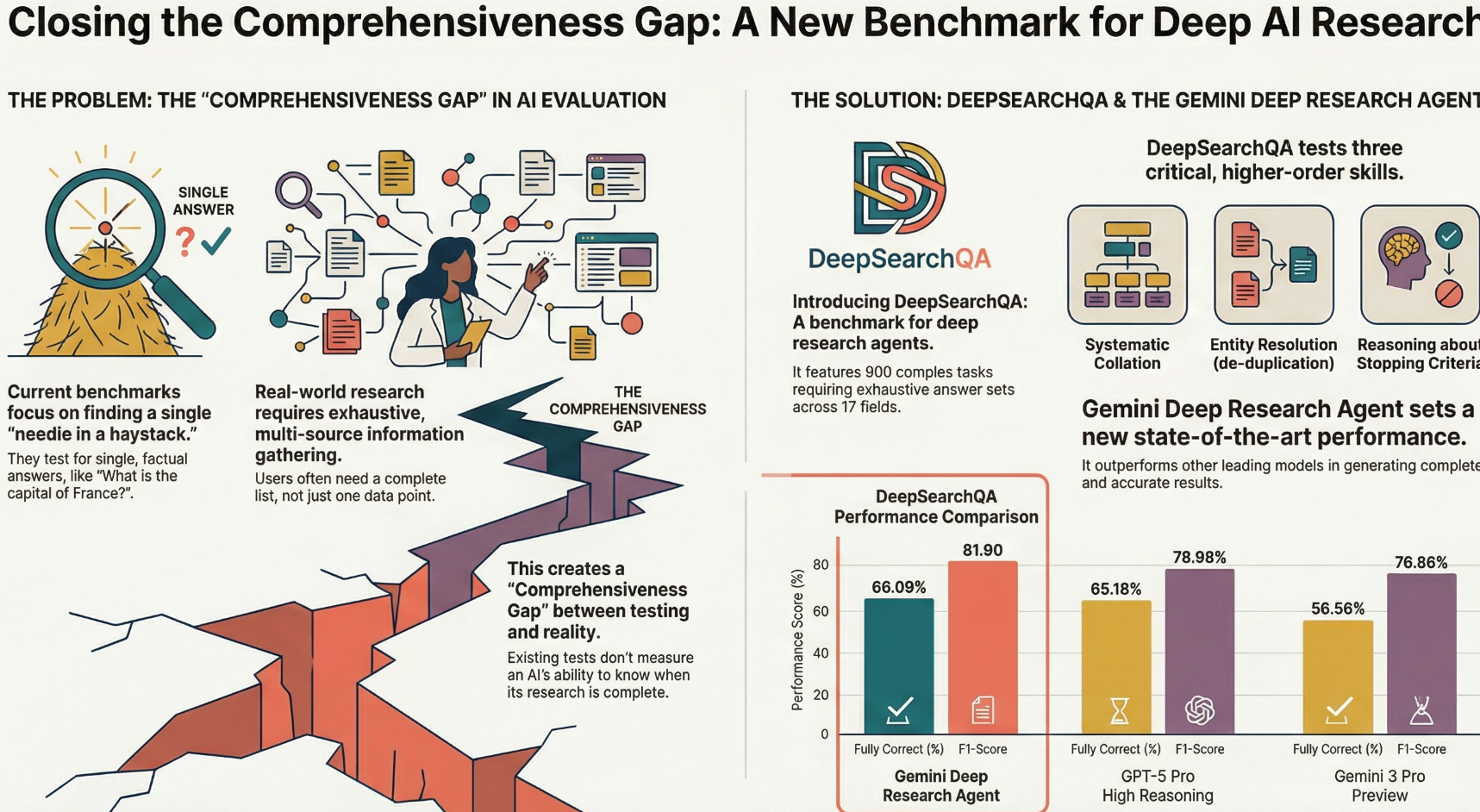
- Comprehensiveness Gap: The evaluation blind spot when agents are optimized for single-answer precision instead of exhaustive, recall-oriented research.
- Set-Based Outcome Evaluation: Agents are graded on the final set’s Precision, Recall, and F1, independent of their search trajectory.
- Categorical Outcome Classes:
- Fully Correct (S=G).
- Fully Incorrect (S∩G=∅).
- Partially Correct (some but not all correct items).
- Correct with Extraneous Answers (R=1.0 with P<1.0; hedging).
- Task Taxonomy:
- Structured Retrieval (“The Search”): Multi-step strategies for obscure information.
- Context Management (“The Assembly”): Synthesis across large or heterogeneous documents.
- Logical Reasoning (“The Thinker”): Constraint solving, inference, and conflict resolution.
- Stopping Criteria under Uncertainty: Distinguishing absence of evidence from evidence of absence within open-ended search.
- Entity Resolution: Deduplicating and normalizing entities with varied surface forms.
- Automated LLM-as-Judge: Using Gemini 2.5 Flash to determine semantic equivalence in submitted sets.
- Static Web Assumption: Prompts anchored to time or static sources to minimize ground-truth drift.
3. Applications in Business
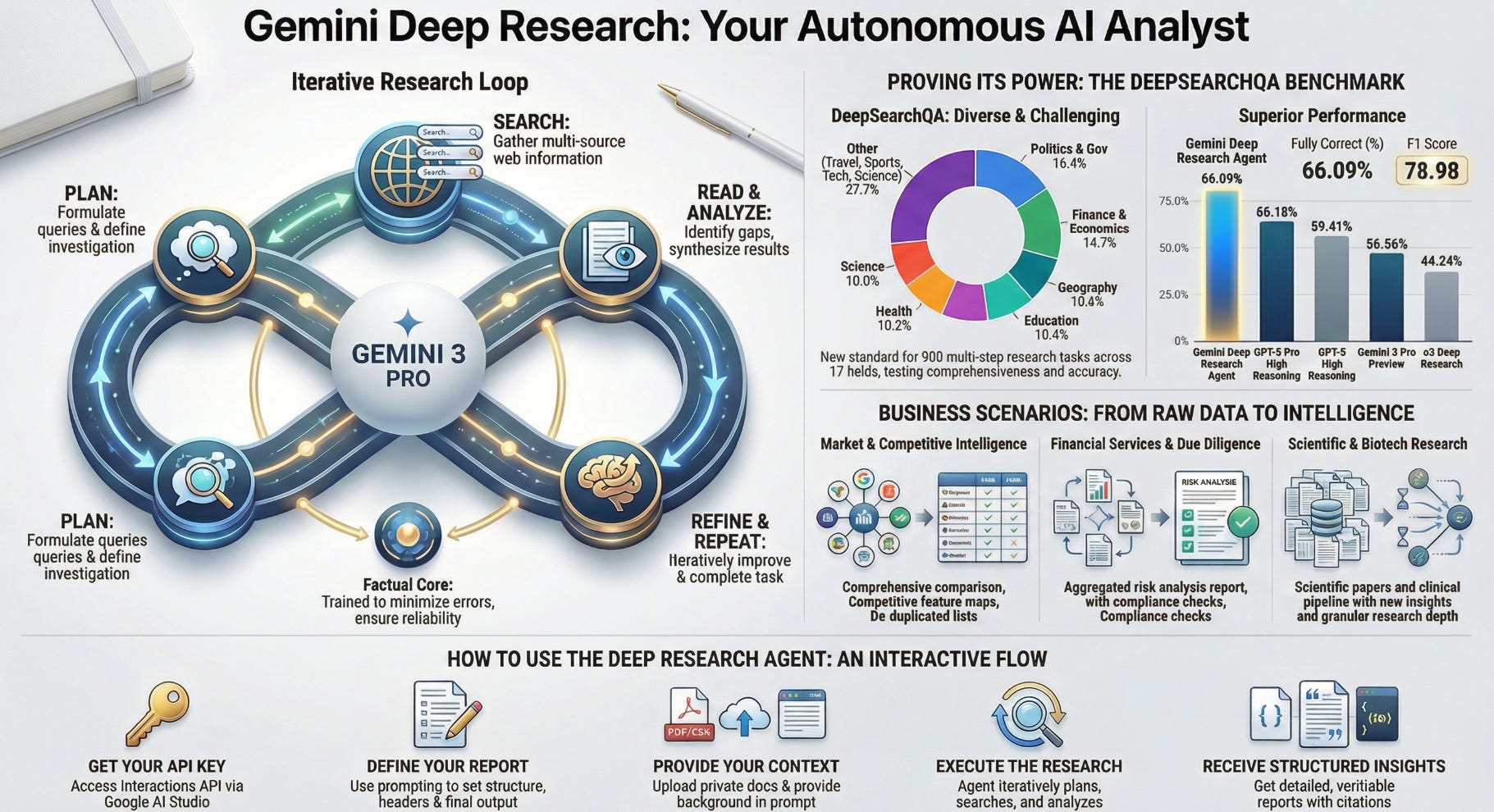
- Market and Competitive Intelligence: Exhaustive product lists, competitor feature comparisons, vendor landscapes; robust de-duplication and source triangulation.
- Financial Analysis and Screening: Constraint-based enumerations (e.g., “all semis with P/E<20 in SE Asia”), cross-source synthesis, high-precision filtering.
- Regulatory and Compliance Monitoring: Comprehensive rule sets, policy changes, jurisdictional exceptions; dynamic stopping once coverage is complete.
- Procurement and Vendor Management: Master lists of qualified suppliers matching multi-attribute constraints; entity resolution across inconsistent naming.
- Risk and Due Diligence: Full coverage of sanctions, litigation, adverse events, or ESG incidents; balancing recall without hedging into false positives.
- Healthcare and Life Sciences R&D: Enumerations of trials, datasets, publications across registries; managing large document contexts with precise filtering.
- Operations and Audit: Exhaustive compliance checks (e.g., transport statistics, safety metrics) with quantifiable completeness and correctness.
- Data/Content Ops: Building clean, deduplicated catalogs from noisy web sources; objective “complete-and-correct” gates for release.
4. Important Insights
- Benchmarks need to evolve beyond single-answer precision to measure recall-oriented exhaustive research: “The limitation of the single-answer approach reveals what we term the Comprehensiveness Gap.”
- Agent loops matter: Deep Research Agents outperform standalone reasoning models; iterative search and verification are required for exhaustive set coverage.
- Hard reasoning threshold and non-linear trade-offs: Smaller models suffer step-function utility drops in deep research tasks; simple semantic search is insufficient.
- The Last Mile Problem: High F1 does not guarantee fully correct set equality; agents must avoid both missing long-tail items and adding extraneous ones.
- Failure modes are multi-stage: Data aggregation, synthesis, tool use, and constraint filtering can each fail distinctly; evaluation must diagnose these.
- Outcome-only scoring is practical but opaque: Without trajectory data, it’s hard to separate sound reasoning from accidental correctness.
- Quotes:
- “This single-answer paradigm... incentivizes precision-first distinct search trajectories... rather than the recall-oriented exhaustive research required...”
- “DeepSearchQA employs a strictly outcome-based evaluation methodology.”
- “Below a certain parameter or compute threshold, agents suffer from trajectory divergence...”
Mind Map
5. Challenges and Solutions
- Main Challenge (Comprehensiveness Gap):
- Challenge: Agents optimized for single answers underperform at exhaustive, multi-step list generation requiring collation, deduplication, and stopping reasoning.
- Solution: A set-based benchmark that forces mastery of precision–recall trade-offs, tests entity resolution, and evaluates stopping criteria via strict outcome classes.
- Key Obstacles:
- Under-Retrieval: Premature stopping misses the long tail.
- Over-Retrieval (Hedging): Perfect recall with incorrect extras lowers precision.
- Entity Ambiguity: Name variants and semantic equivalents inflate or corrupt lists.
- Tool Limitations: Ingesting inaccessible formats (e.g., Excel) or massive contexts.
- Quantitative Estimation Errors: Approximating numbers when exact values are required.
- Static Web Assumption: Ground truth drift and source volatility over time.
- Expert Notions of Solution:
- Systematic Exploration Strategies: Tree/graph-based navigation to avoid missed subpages.
- Advanced Information Synthesis: Robust merge, dedup, and canonicalization across heterogeneous sources.
- Dynamic Stopping Criteria: Reasoning about completeness under uncertainty; distinguish absence of evidence from evidence of absence.
- Process-Aware Extensions: Collect trajectory metadata (pages visited, queries) for diagnostic insight without changing outcome-based scoring.
- Dynamic/Time-Sensitive Tasks: Introduce live prompts to test temporal freshness and real-time retrieval.
- Weighted Relevance: Graded scoring (e.g., nDCG) to reflect core vs peripheral answers.
- Overcoming Limitations and New Techniques:
- LLM-as-Judge for semantic equivalence in set matching.
- Two-tier metric design: Continuous (F1, Precision, Recall) plus categorical outcomes for strict success rates.
- Multi-domain, time-anchored prompts to reduce drift and ensure objective verifiability.
- Broader Implications:
- Benchmarks centered on comprehensiveness will catalyze agent architectures that can “master a topic,” not just fetch an answer.
- Organizations should measure deep research systems by completeness and correctness of final sets, not just correctness of a single item.
- Investment in reasoning capacity and agent loops (planning, memory, tool use) is critical; scaling down models for cost can yield step-function performance drops in research tasks.
Created with AI